



x <- matrix ( rnorm (20 * 2) , ncol = 2)
y <- c( rep (-1, 10) , rep (1, 10) )
x[y == 1, ] <- x[y == 1, ] + 1
plot (x, col = (3 - y))
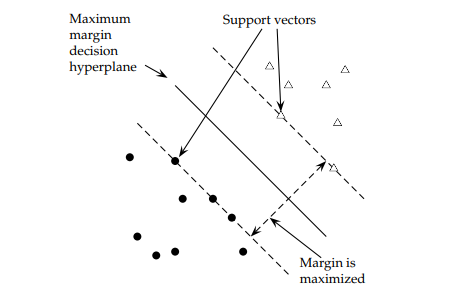
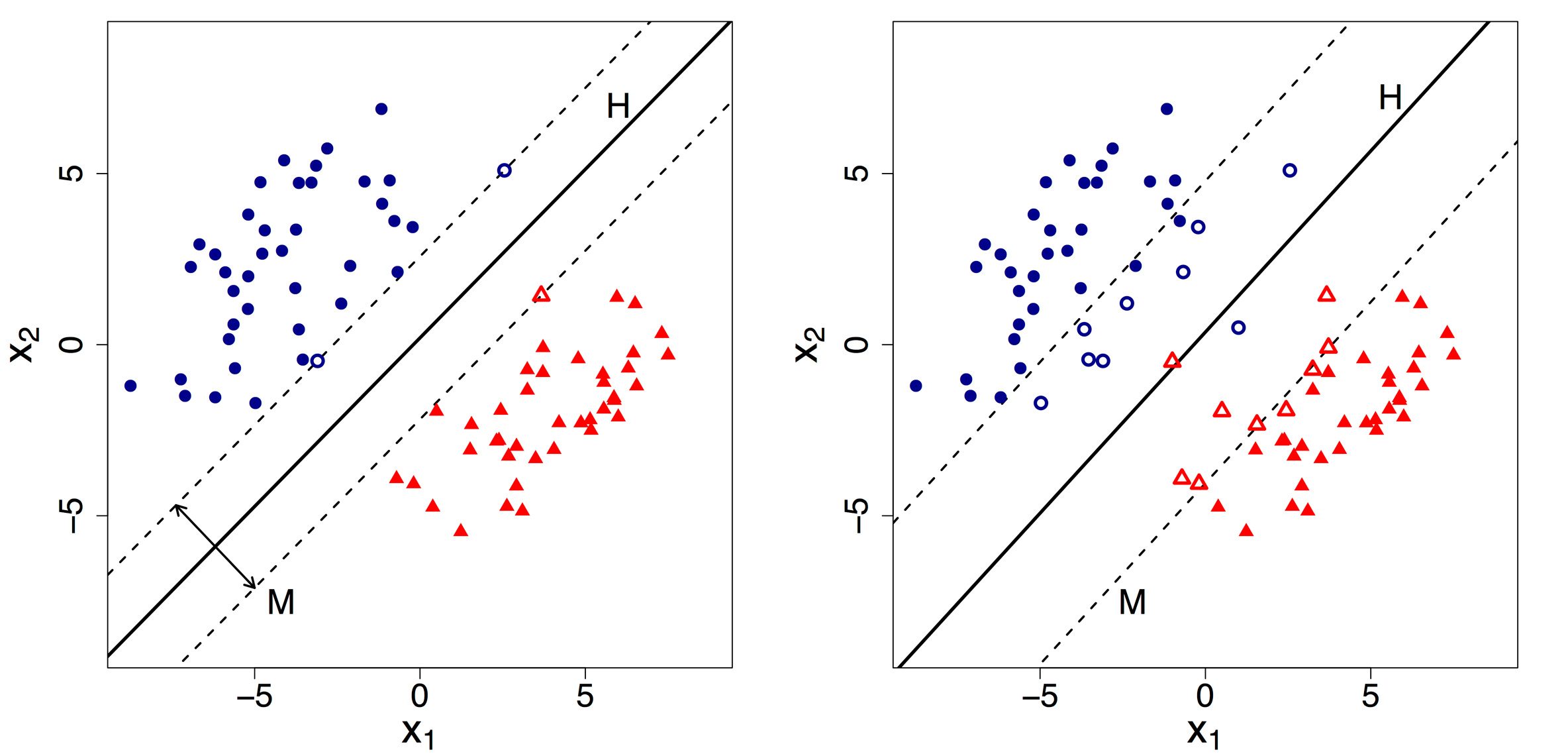
A hyperplane is constructed by maximizing the margin \(M\) of the data points that are farthest from the theoretical margin. The data points that define the outer edge of the margins are known as support vectors.


