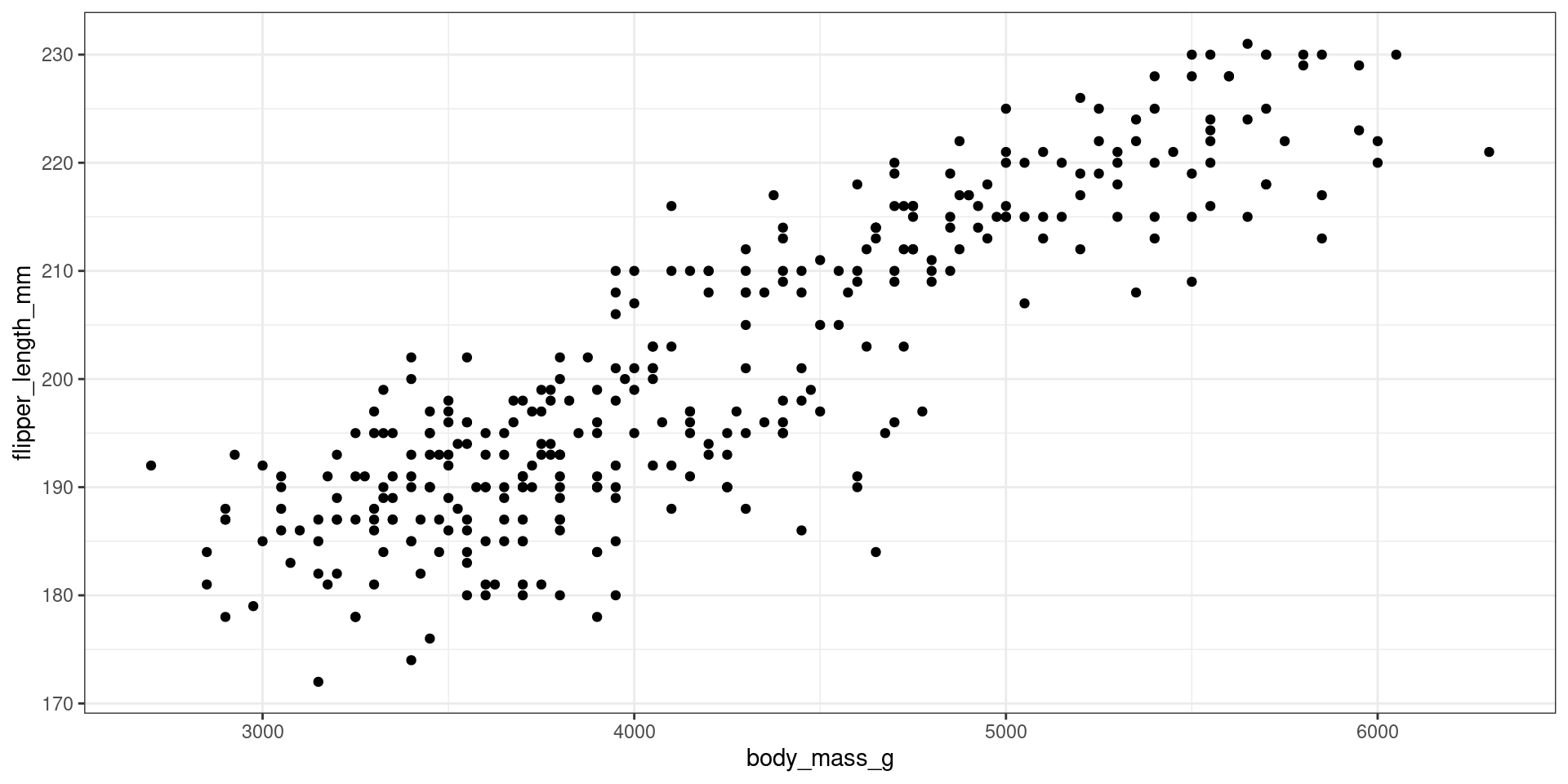
#>
#> Call:
#> lm(formula = flipper_length_mm ~ body_mass_g, data = penguins)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -23.7626 -4.9138 0.9891 5.1166 16.6392
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.367e+02 1.997e+00 68.47 <2e-16 ***
#> body_mass_g 1.528e-02 4.668e-04 32.72 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 6.913 on 340 degrees of freedom
#> (2 observations deleted due to missingness)
#> Multiple R-squared: 0.759, Adjusted R-squared: 0.7583
#> F-statistic: 1071 on 1 and 340 DF, p-value: < 2.2e-16
Interpretation
\[
\hat y = 136.73 + 0.015 x
\]